


Stop Parsing the Same Document Twice - Decoupling OCR from Structured Extraction

If your structured extraction pipeline first runs OCR to digitalize the document, many systems tightly couple OCR and extraction, because extraction is implemented as a downstream step within the same ingestion job.
So when you tweak an invoice structured extraction schema: adjust a field or add an optional key to check for regression. you have to rerun:
PDF → OCR → extraction.
Even though:
- the document didn’t change
- the OCR text didn’t change
If you iterate through 10, 100 or even more schema variants, you recompute OCR every time — adding cost, latency, and slight OCR variability that can affect evaluation.
In Tensorlake, OCR and structured extraction can be decoupled.
Schema iteration can runs on a fixed OCR artifact.
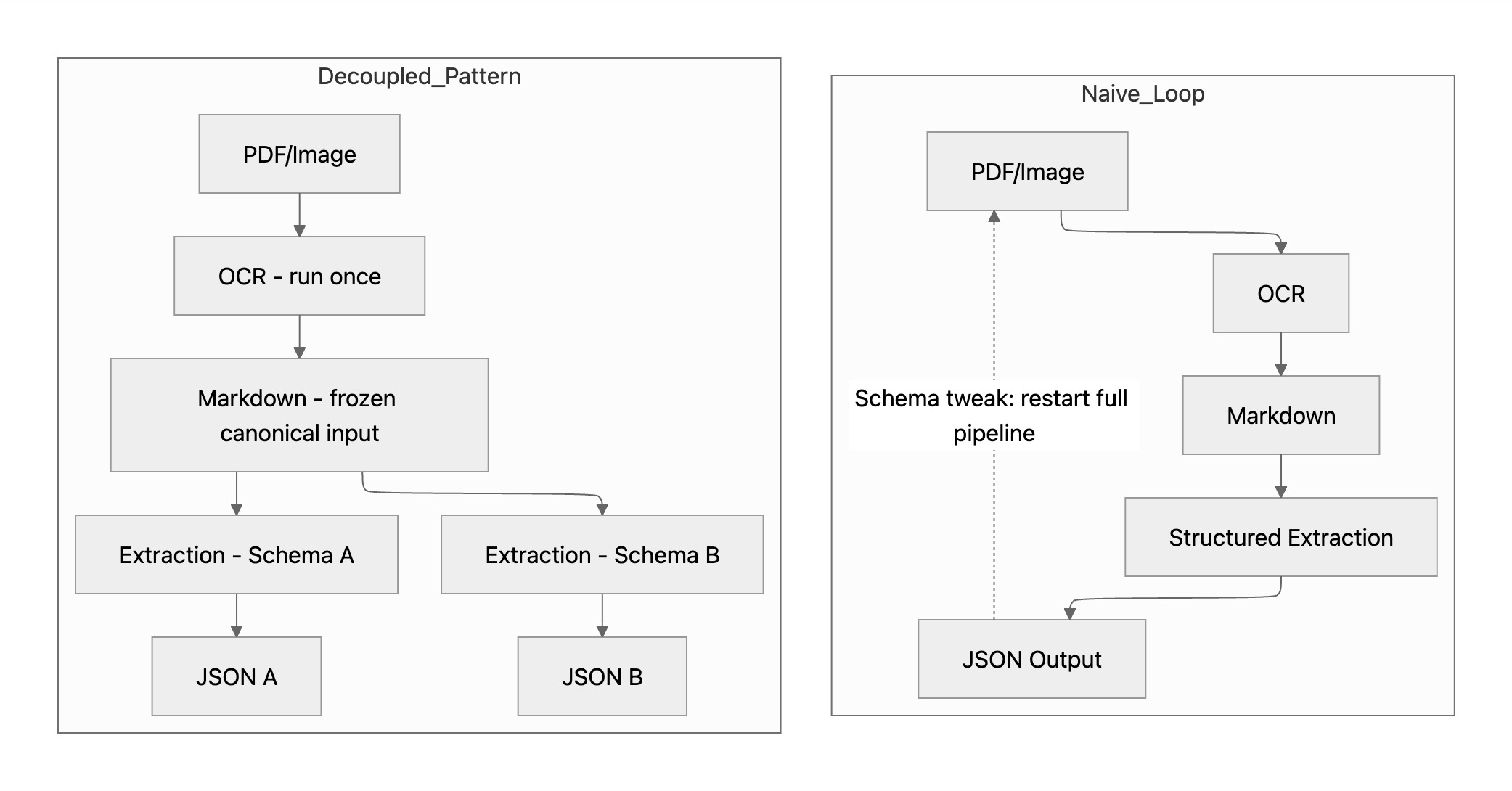
Structured extraction can operate directly on Markdowns
from tensorlake.documentai import DocumentAI
doc_ai = DocumentAI(api_key="YOUR_API_KEY")
# Step 1: Run OCR once
read_job = doc_ai.read(file_id="file_XXX")
read_result = doc_ai.wait_for_completion(parse_id=read_job)
markdown = "\n\n".join(chunk.content for chunk in read_result.chunks)
# Step 2: Reuse Markdown for structured extraction
extract_job = doc_ai.extract(
raw_text=markdown,
structured_extraction_options=[ ... ]
)In Step 2, you only pay for extraction tokens. No document processing cost.
And because the Markdown input is identical every time, your evaluation becomes cleaner — you’re measuring schema changes, not upstream variance.
A Quick Note on Extraction Types
Tensorlake supports two modes of structured extraction:
skip_ocr extraction
Works directly from the PDF or image. The model sees visual layout and spatial context. Ideal for visually complex documents.
LLM-based text extraction
Works from Markdown. This is what raw_text feeds into — and what this caching pattern applies to.
If you’re using skip_ocr, the model requires the original image. There’s no intermediate text representation to cache.
What Happens to Page Boundaries?
One important detail: when you pass raw_text, you’re feeding the entire document Markdown as a single string into structured extraction.
There are no implicit page-level boundaries at this stage.
In the full OCR + extraction pipeline, you can choose to operate:
- Per page
- Per section
- Per fragment
- Pattern-based chunking
- Across the entire document
With raw_text, extraction operates on:
- The full document
- Or pattern-based chunking (e.g. regex-anchored regions)
There’s no automatic page-scoped mode, because page metadata isn’t part of the input anymore — just the Markdown content.
If your document contains cross-page tables, those are already resolved at the OCR layer (via table merging), so the Markdown representation preserves the logical table structure.
For most schema evaluation workflows, this is not a limitation. But it’s important to understand the execution model when designing chunking logic.
When to Use This Pattern
- Schema evaluation loops — OCR once, iterate fast
- A/B testing extraction logic — compare schemas on identical inputs
- Multi-consumer pipelines — one OCR pass, multiple downstream schemas
- Existing text inputs — skip document processing entirely if you already have Markdown
Decoupling ingestion from extraction isn’t just a cost optimization. It’s the foundation for building evaluation layers, rule engines, and decision workflows on top of document AI.
We’ll explore what that looks like when schema iteration becomes a workflow in a follow-up post.
API details for text input and extraction modes are available in the documentation.

Related articles

Get server-less runtime for agents and data ingestion

Tensorlake is the Agentic Compute Runtime the durable serverless platform that runs Agents at scale.
“With Tensorlake, we've been able to handle complex document parsing and data formats that many other providers don't support natively, at a throughput that significantly improves our application's UX. Beyond the technology, the team's responsiveness stands out, they quickly iterate on our feedback and continuously expand the model's capabilities.”
"At SIXT, we're building AI-powered experiences for millions of customers while managing the complexity of enterprise-scale data. TensorLake gives us the foundation we need—reliable document ingestion that runs securely in our VPC to power our generative AI initiatives."
“Tensorlake enabled us to avoid building and operating an in-house OCR pipeline by providing a robust, scalable OCR and document ingestion layer with excellent accuracy and feature coverage. Ongoing improvements to the platform, combined with strong technical support, make it a dependable foundation for our scientific document workflows.”
"For BindHQ customers, the integration with Tensorlake represents a shift from manual data handling to intelligent automation, helping insurance businesses operate with greater precision, and responsiveness across a variety of transactions"
“Tensorlake let us ship faster and stay reliable from day one. Complex stateful AI workloads that used to require serious infra engineering are now just long-running functions. As we scale, that means we can stay lean—building product, not managing infrastructure.”
