


How Tensorlake Solved the DOCX Tracked Changes Problem for Legal Tech

TL;DR
Tracked changes in DOCX files break most OCR and parsing pipelines, resulting in lost revision history, unusable citations, and broken contract intelligence workflows. Tensorlake DocumentAI fixes this by merging Word’s XML change metadata with PDF-level spatial layout, delivering full audit trails, bounding boxes, and comments for every clause, edit, and negotiation note.
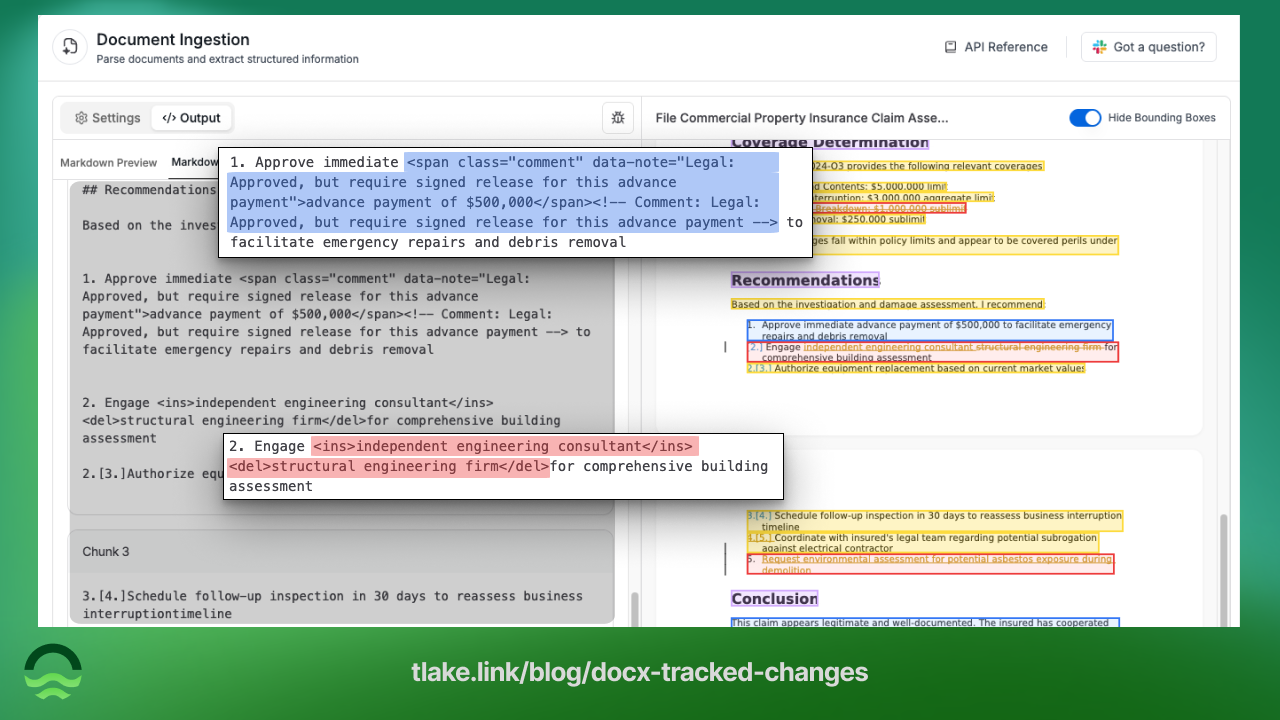
For legal teams building AI-powered contract review systems, tracked changes provide essential context on what changed in the document. This context speeds up the negotiation response process and significantly improves Contract Life Cycle Management (CLM) workflows.
Tensorlake DocumentAI now parses DOCX files with tracked changes while preserving full bounding box and page number metadata for every element. In particular, we extract two key types of metadata from each DOCX file:
- Tracked changes (insertions and deletions), with their exact locations and structure preserved
- Comments, including where and what text they’re attached to
Here's how it works, why it matters for legal tech, and what you can build with it.
Technical contribution by Dr. Shanshan Wang, Founding Data Scientist & Document AI Lead at Tensorlake
The Problem: Why Legal AI Teams Struggle with DOCX Parsing
In legal, finance, and regulated industries, Word documents are heavily used throughout CLM workflows and contain the complete audit trail; not just what the final contract says.
This context is exactly what legal AI systems need to answer questions like:
- "What changes did opposing counsel request in the indemnification clause?"
- "Which liability provisions were flagged by our legal team?"
- "Show me all revisions made after the June 15th conference call."
- "Did the counterparty accept our force majeure language?"
The technical challenge stems from two main limitations. First, reading the XML structure directly captures the text changes, but fails to retrieve bounding boxes for citable extraction. Second, simply converting to PDF results in a loss of metadata; meaning OCR engines cannot understand fonts, strikethroughs, or suggested changes. As a result, standard OCR engines are unable to capture the full context needed for these documents.
For legal tech companies building contract intelligence platforms, the goal is to build a system that understands both what changed and can cite exactly where things are. Tensorlake makes it possible to achieve both simultaneously.
What We Built: Full Audit Trails with Spatial Precision
Tensorlake's Document Ingestion API now parses DOCX files with tracked changes while preserving complete bounding box and page number metadata for every element.
Under the hood, we convert DOCX files to PDF to maintain spatial information, then intelligently merge the tracked changes data from the source XML. The result: you get complete audit trails and precise location data in a single API call.
Here's what you get for every document element:
- Full text content (including accepted and rejected changes)
- Bounding boxes (x, y, width, height coordinates)
- Page numbers (accurate even for multi-column layouts)
- Tracked change metadata (change type)
- Comments (linked to specific text ranges)
This matters because when your LLM answers "What did opposing counsel change in the indemnification clause?", it needs to know:
- Where that clause is (page 12, section 4.2)
- What the original text said
- What the proposed change was
- Which comments reference it
How It Works: Automatic Extraction in One Call
Tensorlake DocumentAI automatically detects and extracts tracked changes and comments when you parse a DOCX file.

When your DOCX contains tracked changes or comments, they are automatically preserved in the HTML markup within the markdown. You get insertions (<ins>), deletions (<del>), and comment ranges (<span class="comment">) alongside the text.
Tracked Changes:
- Insertions:
<ins>inserted text</ins> - Deletions:
<del>deleted text</del>
Comments:
- Comment ranges:
<span class="comment" data-note="comment text">highlighted text</span> - Comment references:
<!-- Comment: comment text -->
Bounding Boxes and Layout:
- The pages attribute gives you the complete visual structure:
1[.code-block-title]Code[.code-block-title]# Access page-level layout information
2for page in result.pages:
3 print(f"Page {page.page_number}")
4 print(f"Dimensions: {page.dimensions}")
5
6 # Each page fragment has precise location data
7 for fragment in page.page_fragments:
8 print(f"Type: {fragment.fragment_type}")
9 print(f"Content: {fragment.content}")
10 print(f"Bounding box: {fragment.bbox}") # [x1, y1, x2, y2]
11 print(f"Reading order: {fragment.reading_order}")This unified output means you can build legal AI systems that understand both the semantic structure (tracked changes, comments) and the visual layout (bounding boxes, page numbers) without making multiple API calls or merging disparate data sources.
You don't need to specify any special modes or flags. It just works:
1[.code-block-title]Code[.code-block-title]from tensorlake import DocumentAI
2
3client = DocumentAI(api_key="your_key")
4
5# Parse any DOCX — tracked changes and comments come automatically
6result = client.parse_and_wait(
7 file="contract_redlined.docx"
8)
9
10# Access the markdown content with tracked changes preserved
11for chunk in result.chunks:
12 print(chunk.markdown)Getting Started
Tensorlake DocumentAI is live in production today. Here's how to try it:
- Sign up for a free API key at cloud.tensorlake.ai
- Install the SDK:
pip install tensorlake Parse your first contract with tracked changes
Check out our full documentation at docs.tensorlake.ai/document-ingestion/parsing/docx for advanced features.
For legal tech teams building on existing infrastructure, we have native integrations ready:
- Snowflake: Direct loading of parsed data with tracked changes
- Databricks: Distributed processing at scale
- Chroma: Vector storage with metadata preservation
Deploy straight to Tensorlake Applications for serverless document processing with automatic scaling and fault tolerance.
What's Next
This is just the start. If you're building contract intelligence, legal AI, or document processing for regulated industries, we'd love to talk.
Book a demo with our team today.
The Bottom Line
For too long, legal tech teams have accepted a false trade-off: either get the document content or get the revision context, but not both.
With Tensorlake's tracked changes support, you don't have to choose anymore. Parse DOCX files with full audit trails and precise spatial metadata in a single API call. Build legal AI systems that understand not just what contracts say, but how they came to say it.
Stop losing half your data. Start building better contract intelligence.

Related articles

Get server-less runtime for agents and data ingestion

Tensorlake is the Agentic Compute Runtime the durable serverless platform that runs Agents at scale.
“With Tensorlake, we've been able to handle complex document parsing and data formats that many other providers don't support natively, at a throughput that significantly improves our application's UX. Beyond the technology, the team's responsiveness stands out, they quickly iterate on our feedback and continuously expand the model's capabilities.”
"At SIXT, we're building AI-powered experiences for millions of customers while managing the complexity of enterprise-scale data. TensorLake gives us the foundation we need—reliable document ingestion that runs securely in our VPC to power our generative AI initiatives."
“Tensorlake enabled us to avoid building and operating an in-house OCR pipeline by providing a robust, scalable OCR and document ingestion layer with excellent accuracy and feature coverage. Ongoing improvements to the platform, combined with strong technical support, make it a dependable foundation for our scientific document workflows.”
"For BindHQ customers, the integration with Tensorlake represents a shift from manual data handling to intelligent automation, helping insurance businesses operate with greater precision, and responsiveness across a variety of transactions"
“Tensorlake let us ship faster and stay reliable from day one. Complex stateful AI workloads that used to require serious infra engineering are now just long-running functions. As we scale, that means we can stay lean—building product, not managing infrastructure.”
