


Gemini 3 is Now Available as an OCR Model in Tensorlake

TL;DR
Tensorlake has integrated the new Gemini 3 model as an advanced OCR engine in its Document Ingestion API.
Gemini 3 is now available within Tensorlake
Google’s Gemini model since 2.5 Flash has been great at Document Parsing. The latest Gemini 3 pushes the envelope even further. It has the lowest edit distance(0.115) on OmniDocBench compared to GPT-5.1(0.147) and Claude Sonnet 4.5.
Starting today, you can start using Gemini as an OCR Engine with Tensorlake’s Document Ingestion API. You can ingest Documents in bulk, and convert them into Markdown, classify pages or extract structured data using JSON schema. Tensorlake will take care of queuing, working with rate limits and sending you webhooks as documents are processed.
We put Gemini 3 to the test inside Tensorlake, and the results on "hostile" document layouts were immediate.
Case Study 1: Table Structure Recognition
Document: Google 2024 Environmental Report
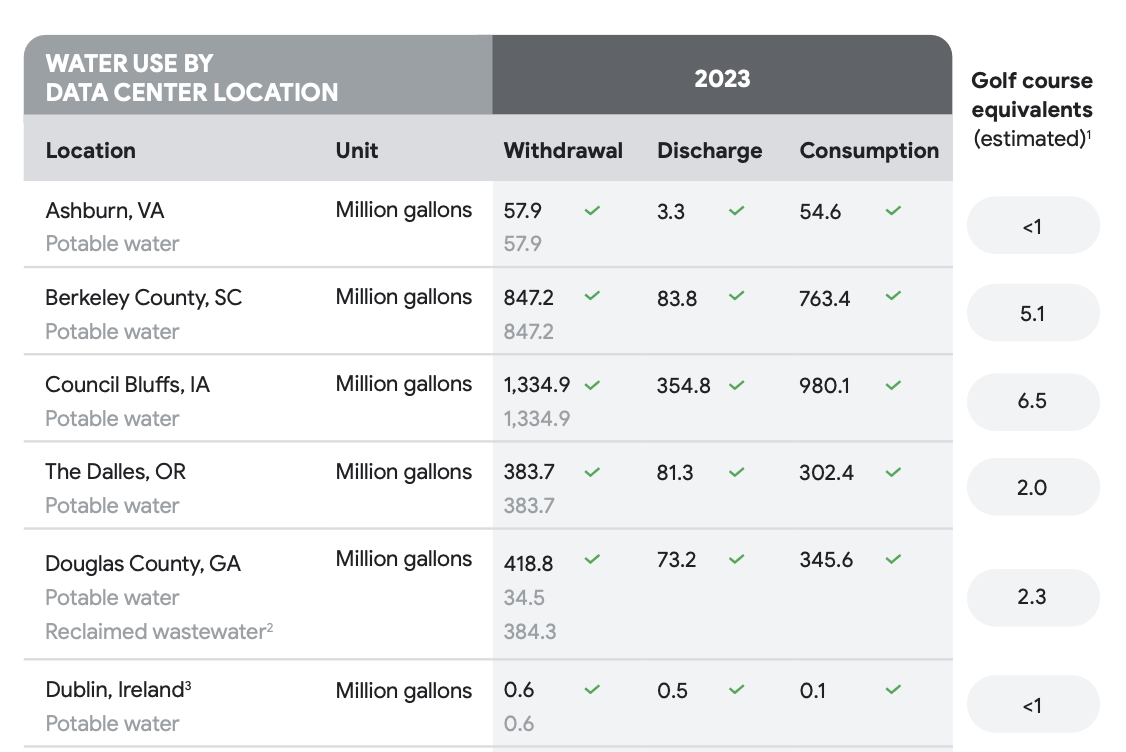
Financial and scientific reports use visual cues, like indentation, floating columns, and symbols, to convey meaning. To test this, we fed the complex "Water Use" table from the Appendix into Gemini 3.
The Challenge
The table is semi wireless - some lines separating some of the rows while the columns have no boundaries. The column on the right is disconnected to the main block.
The Gemini 3 Result: Visual Understanding
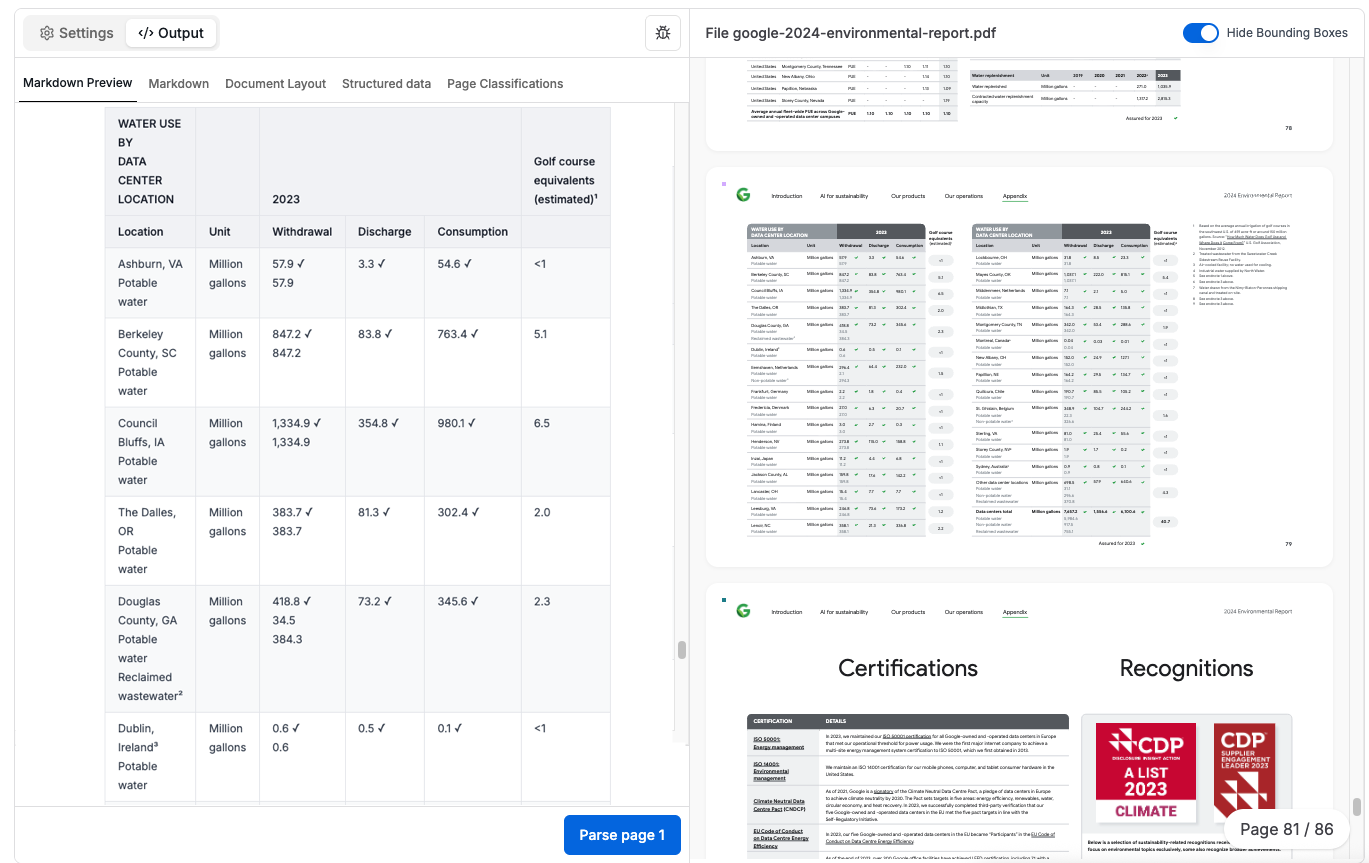
Gemini3 does a perfect job on understanding this table. This is a screenshot from the Tensorlake Cloud Dashboard.
Case Study 2: VQA + Structured Output
Document: House Floor Plans
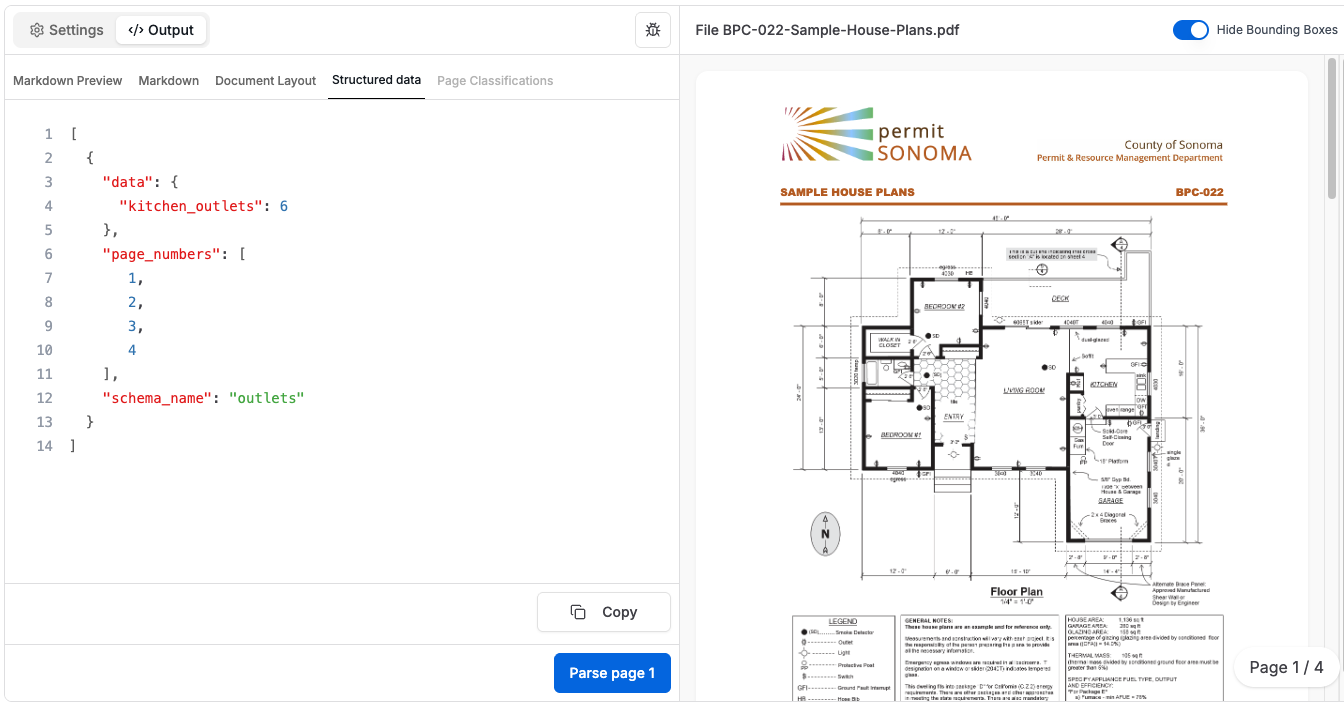
We wanted to test if Gemini 3 could parse visual symbols on construction documents. We fit Gemini3 into Tensorlake’s Structured Extraction pipeline.
The Input: A raw PDF of a house plan and a Pydantic schema defining the exact fields we needed (e.g., kitchen_outlets: int, description: Number of standard and GFI electrical outlets, as noted by the legend icon labeled "outlet", that are found in the kitchen and dining nook.).
For reference, here is the kitchen+dining nook area.
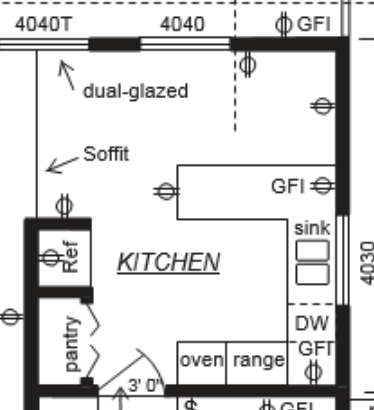
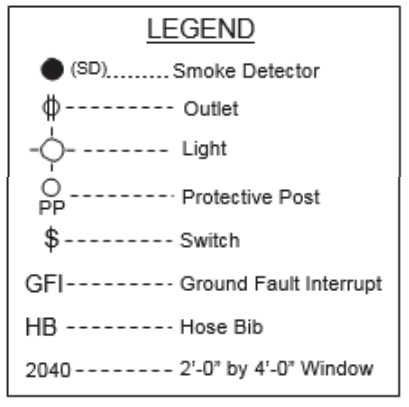
The circle with two lines are the outlets, as per the legend on the same page:
The Challenge
There is no text label saying "Outlet" on the diagram, it is only associated with the symbol in the legend The model must identify the specific circle-and-line icon defined in the legend, spatially constrain its search to the visual boundaries of the "Kitchen," and aggregate the count into our JSON structure.
The Result
Gemini 3 successfully understood the visual diagram. It returned a valid JSON object with 6 outlets, correctly distinguishing them from nearby data ports and switches.
Tensorlake blends specialized OCR models and VLMs into a set of convenient APIs. While you could call the Gemini API directly, you would be rebuilding many undifferentiated aspects of a production pipeline. Gemini 3 is now fully integrated with Tensorlake DocAI APIs to read, classify, and extract information from documents.
Tensorlake solves the two biggest headaches of building Document Ingestion APIs using VLMs:
- Bulk Ingestion & Rate Limits: From our observation Gemini3 doesn’t handle spiky traffic very well. Throwing 10,000 documents at it will trigger errors due to strict quotas. Tensorlake manages the queue, handling back-off and retries automatically so you can ingest massive datasets without hitting 429 errors.
- Chunking Large Files: Tensorlake automatically chunks large documents into chunks of 25 pages to make sure Gemini is able to extract even the most dense pages. We ensure that the output token limit of 64k is not exceeded.
When to use (and NOT use) Gemini 3
Use Gemini 3 when:
- Complex Visual Reasoning is required: You need to correlate a chart's color legend to a data table, or count symbols on a blueprint (as shown in the house plan example).
Do NOT use Gemini 3 when:
- You need bounding boxes for citation: Gemini 3 does not perform layout detection of objects in documents. If your application requires strict Bounding Boxes to highlight exactly where a specific paragraph or number came from.
- You need strict text style and font detection: Visual nuances like strikethroughs, underlines, or specific font colors are often ignored by VLMs, which focus on the "content" rather than the style.
For these tasks, you should use one of Tensorlake’s specialized models, like Model03.
How to use Gemini 3 with Tensorlake
Playground
Gemini 3 is available today in the Tensorlake Playground for experimentation:
Or you can select it with our HTTP API or SDK:
1[.code-block-title]Code[.code-block-title]from tensorlake.documentai import DocumentAI, ParsingOptions
2
3client = DocumentAI()
4
5parse_id = client.read(
6 file_url="https://tlake.link/docs/real-estate-agreement",
7 parsing_options=ParsingOptions(
8 ocr_model="gemini3"
9 )
10)
11
12result = client.result(parse_id)
13)What's Next
Document Ingestion has a lot of edge cases. We want our users to always have access to state of the art models so that they can solve their use cases fairly quickly by changing various aspects of the OCR pipelines with very minimal code changes.
We will add more Foundation Models as OCR model options in Tensorlake’s Document Ingestion API.
Want to discuss your specific use case?
Schedule a technical demo with our team.
Questions about the benchmark?
Join our Slack community

Related articles

Get server-less runtime for agents and data ingestion

Tensorlake is the Agentic Compute Runtime the durable serverless platform that runs Agents at scale.
“With Tensorlake, we've been able to handle complex document parsing and data formats that many other providers don't support natively, at a throughput that significantly improves our application's UX. Beyond the technology, the team's responsiveness stands out, they quickly iterate on our feedback and continuously expand the model's capabilities.”
"At SIXT, we're building AI-powered experiences for millions of customers while managing the complexity of enterprise-scale data. TensorLake gives us the foundation we need—reliable document ingestion that runs securely in our VPC to power our generative AI initiatives."
“Tensorlake enabled us to avoid building and operating an in-house OCR pipeline by providing a robust, scalable OCR and document ingestion layer with excellent accuracy and feature coverage. Ongoing improvements to the platform, combined with strong technical support, make it a dependable foundation for our scientific document workflows.”
"For BindHQ customers, the integration with Tensorlake represents a shift from manual data handling to intelligent automation, helping insurance businesses operate with greater precision, and responsiveness across a variety of transactions"
“Tensorlake let us ship faster and stay reliable from day one. Complex stateful AI workloads that used to require serious infra engineering are now just long-running functions. As we scale, that means we can stay lean—building product, not managing infrastructure.”
